-
Hey, guest user. Hope you're enjoying NeoGAF! Have you considered registering for an account? Come join us and add your take to the daily discourse.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Get Stable diffusion locally on your PC (RTX card needed) no restrictions and no censorship.
- Thread starter Tumle
- Start date





I see that Princess Peach/Resident Evil crossover project is going wellbeen using SDXL .9 for the past week and really impressed. I just created a sdxl cain lora from robocop2, 60 images @ 1024x1024 took 6-7 hours on a 4070ti, gonna post results later, so here's my peach sdxl lora for now.

Lord Panda
The Sea is Always Right
I see that Princess Peach/Resident Evil crossover project is going well
I was thinking more Peach x Annabelle

Mr1999
Gold Member
I had to scrap my initial lora, and will scrap this one out as well once version 1 comes out, which I believe is very soon? I think tomorrow no? Cain seemed a little bit harder to pull off, so many features on this thing. I will try to do better when version 1 comes out or go onto something different, something easier for now once I figure SDXL out more and other issues with it are sorted out.
SDXL seems a bit more touchy with cfgs, not just talking about the prompts, but there are other options that sway which way your end result is going to go and A1111 at the moment even though it does have support for SDXL, I had to look for these settings when its right in front of you with ComfyUI. Overall it seemed like SDXL took more fine tuning to get decent results. Alot of happy accidents did occur which I have included here.
EDIT: For my 1.0 project I will do Skeksil from the Dark Crystal, lol. Always loved The Dark Crystal and there's ton of stuff there, might also do a style but that's getting ahead of myself. Skeksil it is!








SDXL seems a bit more touchy with cfgs, not just talking about the prompts, but there are other options that sway which way your end result is going to go and A1111 at the moment even though it does have support for SDXL, I had to look for these settings when its right in front of you with ComfyUI. Overall it seemed like SDXL took more fine tuning to get decent results. Alot of happy accidents did occur which I have included here.
EDIT: For my 1.0 project I will do Skeksil from the Dark Crystal, lol. Always loved The Dark Crystal and there's ton of stuff there, might also do a style but that's getting ahead of myself. Skeksil it is!
Last edited:



Mr1999
Gold Member
Sup guys, here are my new loras I created. Should not need to say who they are, self explanatory, I hope. Next is battle angel alita and then maschinen krieger. I will get beter results with those two, not much content for inspector gadget so i had to take pictures of my blitzway inspector gadget figure, turned out okay, i will not need to do this with either of the two listed.









Last edited:
Makoto-Yuki
Gold Member
you can download it and mess about with it. i'm no expert but i think you only need to train if you want to add in your own stuff. I was trying to make a LoRA but it's too confusing for me. i couldn't get it to work. i did some text inversion embedding which i had to train.I've been playing with midjourney for a few months and have been thinking of trying out stable diffusion. Do you still need to train it, or can you just download and prompt whatever?
Tumle
Member
You don’t have to train it it there is a plethora of checkpoints and others stuff you can download from here : https://civitai.com/I've been playing with midjourney for a few months and have been thinking of trying out stable diffusion. Do you still need to train it, or can you just download and prompt whatever?
Mr1999
Gold Member
you can download it and mess about with it. i'm no expert but i think you only need to train if you want to add in your own stuff. I was trying to make a LoRA but it's too confusing for me. i couldn't get it to work. i did some text inversion embedding which i had to train.
Adding your stuff is half the fun. Don't give up, there's plenty of tutorials on youtube for creating Lora using Kohya. I believe you need a minimum of 12GB for creating SDXL Lora but I could be wrong. I no longer use my 4070Ti to train stuff with, maybe in the winter but not with this his humidity. I just rent a 4090 instead, which is a little bit more involved but once you get it down its rather easy.
I rent it out from runpod.io, I basically deploy an instance with kohya template which pre-installs kohya, then I connect to jupyter notebook, then pip install gdown, and then !gdown https://drive.google.com/uc?id=????????????????? my sdxl safetensor from my gdrive I had uploaded it on. I then put said safetensor into model folder, images with txt captions into image/100_urlora folder and then create log folder, from there I load terminal and cd into Kohya_ss, type source venv/bin/activate and then bash gui.sh --share, I click on the link it shows and then use Kohya regularly. Or if you dont really care about making your own stuff, there are tons of stuff on civitai as Tumle suggested.
I don't share my Loras because studios are actively pursuing those who are uploading them. I believe square enix was one of them. It's completely out of control now though. I like to make my own stuff, niche stuff is still very rare.
Last edited:
Makoto-Yuki
Gold Member
I did install Kohya or at least I think it was that lol but when it came to tagging my photos it kept getting an error and I couldn't figure out what was causing it or find any solutions so gave up. I might give it another shot maybe I installed it wrong but I was following a guide step by step.Adding your stuff is half the fun. Don't give up, there's plenty of tutorials on youtube for creating Lora using Kohya. I believe you need a minimum of 12GB for creating SDXL Lora but I could be wrong. I no longer use my 4070Ti to train stuff with, maybe in the winter but not with this his humidity. I just rent a 4090 instead, which is a little bit more involved but once you get it down its rather easy.
I rent it out from runpod.io, I basically deploy an instance with kohya template which pre-installs kohya, then I connect to jupyter notebook, then pip install gdown, and then !gdown https://drive.google.com/uc?id=????????????????? my sdxl safetensor from my gdrive I had uploaded it on. I then put said safetensor into model folder, images with txt captions into image/100_urlora folder and then create log folder, from there I load terminal and cd into Kohya_ss, type source venv/bin/activate and then bash gui.sh --share, I click on the link it shows and then use Kohya regularly. Or if you dont really care about making your own stuff, there are tons of stuff on civitai as Tumle suggested.
I don't share my Loras because studios are actively pursuing those who are uploading loras, I believe square enix was one of them. It's completely out of control now though. I like to make my own stuff, niche stuff is still very rare.
Mr1999
Gold Member
What was the error do you remember, I use blip captioning, it will download data if you have never used it before and then generate txt files, once I have the txt I go modify them, there are scripts to help with this.I did install Kohya or at least I think it was that lol but when it came to tagging my photos it kept getting an error and I couldn't figure out what was causing it or find any solutions so gave up. I might give it another shot maybe I installed it wrong but I was following a guide step by step.
Makoto-Yuki
Gold Member
I can't remember. Something about cuda so I thought it was a memory issue. I'll try it again tomorrow.What was the error do you remember, I use blip captioning, it will download data if you have never used it before and then generate txt files, once I have the txt I go modify them, there are scripts to help with this.
When I was doing text inversion I used stable diffusion to generate tags then I'd edit them if needed but since I was following the guide I tried doing it with kohya.



IntentionalPun
Ask me about my wife's perfect butthole
What is a loRA?
Mr1999
Gold Member
Im sure there is a technical answer to this and anyone can correct me if im wrong, but its basically a file you create with whatever you are trying to train, it can be an object or a person, or even a style, this allows you to mix it with checkpoints. For example if you want the style of the movie Coraline, which this is my next project, you take a lot of pictures of the style you want, probably more images than you would do a person,, and then create a lora with it, and then you can create whatever you want using said style lora,, its a little bit more involved than that but thats the tldr i guess.What is a loRA?
Last edited:
Makoto-Yuki
Gold Member
Say you wanted to make silly images of yourself then you'd take a bunch of photos of yourself and train it into a LoRA so instead of getting a boring generic image you could make the image look like yourself. or say you had a favourite movie/TV show with a distinct artstyle then you could train a LoRA so that the output was in the same style as that. I downloaded an Arcane (League of Legends show) LoRA that made everything look like it was from that show. There are a bunch of Ghibli LoRAs too. It could also be you want your backgrounds to be a certain scene.What is a loRA?
you need images of your subject, tag them, and train them. it'll create a file and when you're doing your prompt you insert the LoRA prompt and it'll use it.
IntentionalPun
Ask me about my wife's perfect butthole
Ah thanks guys, that makes sense.




Lord Panda
The Sea is Always Right
Tried Kling AI by creating video from one stable diffusion image. Pretty nice results for using one sentence.
My brother's into building and painting models.
Eg:


I ran these through Kling for a laugh:
Ironbunny
Member
My brother's into building and painting models.
Eg:
I ran these through Kling for a laugh:
Its pretty cool stuff for something thats free. Thinking of getting the paid subscription to bring to life some of the old family world war 2 photos.
llien
Banned
CUDA card is not needed.
Just grab this:

My friend told me that censorship can be defeated via editing models after program starts.
Just grab this:
My friend told me that censorship can be defeated via editing models after program starts.
Someone just did. Although, ironically, you'd need an AMD GPU (I think).Why does this have to use weird shit like Python and web browser GUIs, why can't someone just package it as a regular Windows exe with a basic interface?
Last edited:
Ironbunny
Member
CUDA card is not needed.
Just grab this:
My friend told me that censorship can be defeated via editing models after program starts.
Someone just did. Although, ironically, you'd need an AMD GPU (I think).
Gotta try that.
IntentionalPun
Ask me about my wife's perfect butthole
How well does this thing work for big beefy labia?
winjer
Member
Gotta try that.
If you are confortable with a command line, try Ollama. Plenty of LLMs for text and image generation.
For example, Lamma 3.2. Is a 3B parameter LLM that is super fast even on non RTX cards.
Jinzo Prime
Member
Brother, I needed this! I've got an AMD GPU and getting AI set up on it isn't easy.CUDA card is not needed.
Just grab this:
My friend told me that censorship can be defeated via editing models after program starts.
Someone just did. Although, ironically, you'd need an AMD GPU (I think).
Salz01
Member
I wish some like this was for Apple silicon, M1 chips…. I want that.CUDA card is not needed.
Just grab this:
My friend told me that censorship can be defeated via editing models after program starts.
Someone just did. Although, ironically, you'd need an AMD GPU (I think).
Tumle
Member
Not a Mac user and I don’t know how user friendly you want it.. but heard good things about this app:I wish some like this was for Apple silicon, M1 chips…. I want that.
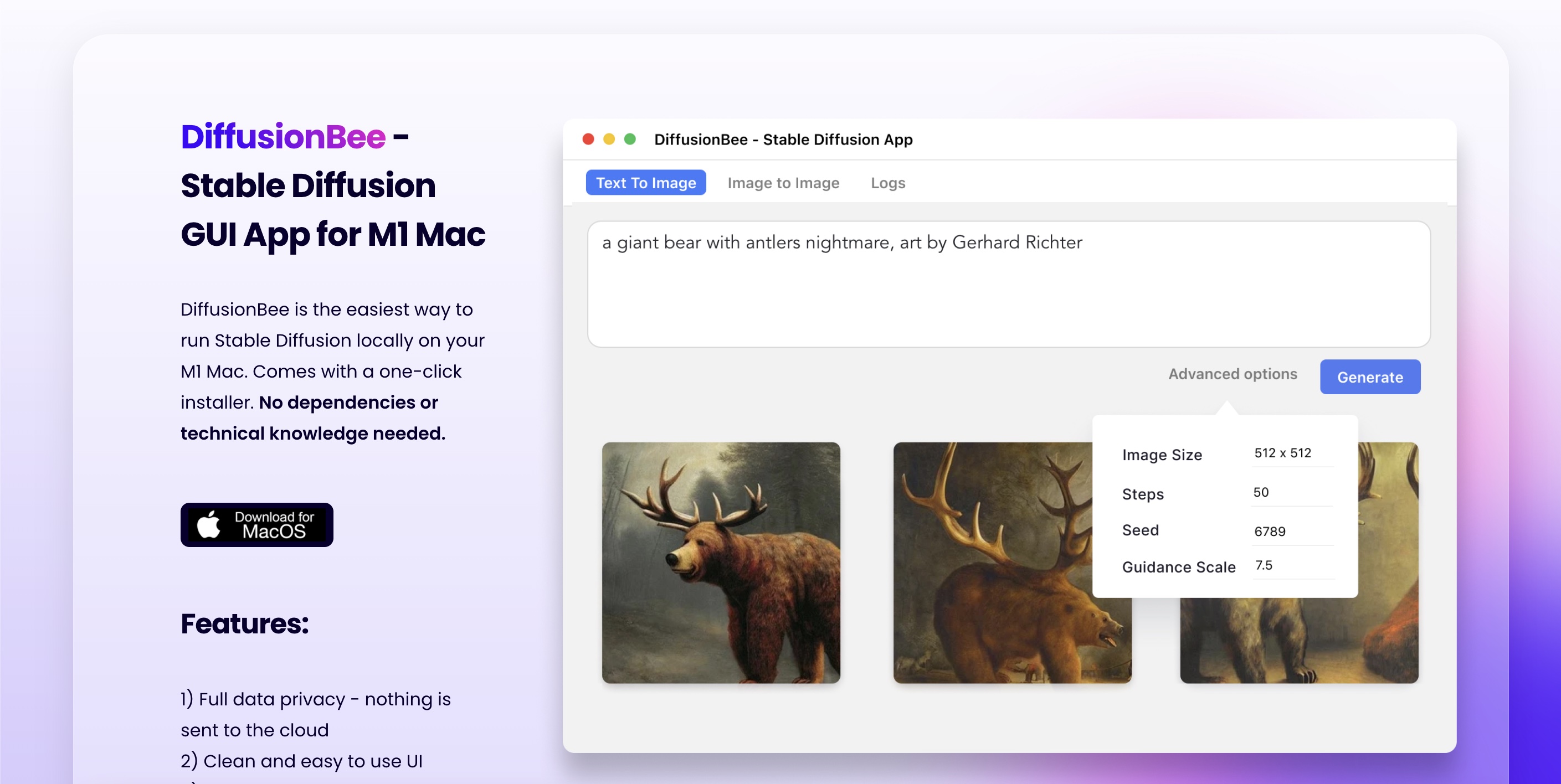
DiffusionBee - Stable Diffusion App for AI Art
DiffusionBee is the easiest way to generate AI art on your computer with Stable Diffusion. Completely free of charge.
 diffusionbee.com
diffusionbee.com
Installation guide
GitHub - divamgupta/diffusionbee-stable-diffusion-ui: Diffusion Bee is the easiest way to run Stable Diffusion locally on your M1 Mac. Comes with a one-click installer. No dependencies or technical knowledge needed.
Diffusion Bee is the easiest way to run Stable Diffusion locally on your M1 Mac. Comes with a one-click installer. No dependencies or technical knowledge needed. - divamgupta/diffusionbee-stable-di...
 github.com
github.com
Last edited:
Salz01
Member
Thanks yes. Have Diffusion Bee. But it’s mostly used for text to image. T2V or I2V gets harder to do on Mac.Not a Mac user and I don’t know how user friendly you want it.. but heard good things about this app:
DiffusionBee - Stable Diffusion App for AI Art
DiffusionBee is the easiest way to generate AI art on your computer with Stable Diffusion. Completely free of charge.
Installation guide

GitHub - divamgupta/diffusionbee-stable-diffusion-ui: Diffusion Bee is the easiest way to run Stable Diffusion locally on your M1 Mac. Comes with a one-click installer. No dependencies or technical knowledge needed.
Diffusion Bee is the easiest way to run Stable Diffusion locally on your M1 Mac. Comes with a one-click installer. No dependencies or technical knowledge needed. - divamgupta/diffusionbee-stable-di...
Tumle
Member
Ah ok, I understand nowThanks yes. Have Diffusion Bee. But it’s mostly used for text to image. T2V or I2V gets harder to do on Mac.
 you can’t use ComfyUI?
you can’t use ComfyUI?Oh I forgot the easy to use part

Last edited: